ROBIN WITTE
Data Science | Machine Learning | Computer Vision

ROBIN WITTE
B. Sc. Angewandte Informatik
mit Anwendungsfach ‚Computational Neuroscience‘
Student im Masterstudiengang
‚Artificial Intelligence and Data Science M. Sc.‘
Köln
Über mich:
Ich bin Robin Witte, 27 Jahre alt und studiere zurzeit den Masterstudiengang Artificial Intelligence and Data Science an der Heinrich-Heine-Universität Düsseldorf. In diesem Masterstudiengang beschäftige ich mich mit den mathematischen, statistischen und algorithmischen Grundlagen künstlicher Intelligenz. Neben den Perspektiven der Informatik und der Statistik, betrachte ich dabei das Gebiet der komplexen Datenverarbeitung zusätzlich aus den Blickwinkeln der Biowissenschaften, der Medizin, der Linguistik und der Wirtschaft. Zuvor habe ich an der Friedrich-Schiller-Universität Jena erfolgreich den Bachelorstudiengang Angewandte Informatik mit dem Anwendungsfach Computational Neuroscience absolviert, in dessen Rahmen ich mich neben regulären Informatikvorlesungen auch mit medizinsicher Datenverarbeitung, sowie mit maschinellen Lernverfahren und Grundlagen künstlicher Neuronaler Netze beschäftigt habe. Meine Interessensgebiete gestalten sich vielfältig und reichen von Optimierung, über statistische Lerntheorie bis hin zu tiefen Lernverfahren und Netzwerkanalyse.
Ausbildung
2012 - 2016
Westfälische Hochschule Standort Bocholt
Studienfach: Bionik (B.Sc.)
ohne Abschluss – Alle Leistungen bis auf die Bachelorarbeit erbracht
2016 - 2019
Friedrich-Schiller-Universität Jena
Studienfach: Angewandte Informatik (B.Sc.)
Anwendungsfach: Computational Neuroscience
Abschluss: B.Sc.
2019 - Heute
Heinrich-Heine-Universität Düsseldorf
Studienfach: Artificial Intelligence and Data Science (M.Sc.)
Praktika
02. 2016 - 04. 2016
Eberhard Karls Universität Tübingen
Lehrstuhl Kognitive Systeme
Grundlagenstudien im Bereich Autonome Mobile Robotik
04. 2019 - 06. 2019
Universitätsklinikum Jena
Structural Brain Mapping Group
Verarbeitung von MRT-Daten unter Anwendung maschineller Lernverfahren
Nebenjobs
2014 - 2015
Westfälische Hochschule Standort Bocholt
Lehrstuhl Biologie
Studentische Hilfskraft
2017 - 2019
Universitätsklinikum Jena
Hans Berger Department of Neurology
Studentische Hilfskraft
Veröffentlichung
2019
Schmidt, A., Witte, R., Swiderski, L., Zöllkau, J., Schneider, U., & Hoyer, D.
Advanced automatic detection of fetal body movements from multichannel magnetocardiographic signals
Physiological measurement 40.8
Programmiersprachen
Python
Matlab
R
C
Java
HTML
CSS
Projekte
Recommender system: Using singular value decomposition as a matrix factorization approach
The task of a recommender system is to recommend items, that fi t the user’s taste. The approach, that makes use of only user activities of the past, is termed collaborative fi ltering. Given a not fully specifi ed user-item ratings Matrix, a collaborative filtering algorithm estimates robustly all missing entries. In this project I described a collaborative fi ltering algorithm, that uses singular value decomposition (SVD) as a form of matrix factorization. The approach is based on Simon Funk’s method, which was invented for the Netflix-Challenge.
The mathematical description of the method can be found in the PDF-File. The code was written in a Jupyter notebook, which can be found on GitHub.
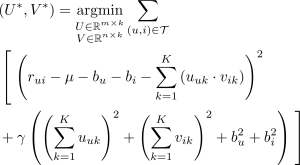
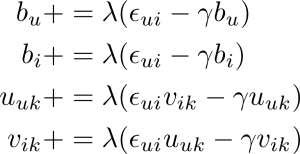
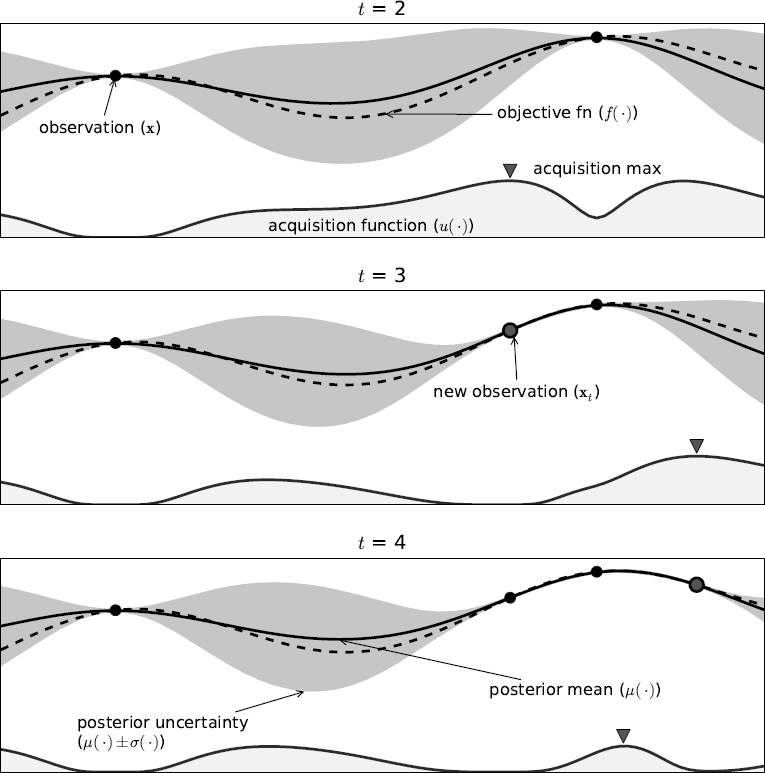
Bayessche Optimierung: Theoretische Grundlagen der Hyperparameteroptimierung
Bayessche Optimierung ist eine globale Optimierungsmethode, die sich insbesondere für die Hyperparameteroptimierung von maschinellen Lernverfahren eignet. Im Gegensatz zu anderen Optimierungsverfahren wird bei der Bayesschen Optimierung ein probabilistisches Modell für die Zielfunktion erstellt und dieses dann in einem iterativen Verfahren durch Hinzunahme weiterer Datenpunkte aktualisiert und verbessert. Hierbei ist der Grundgedanke, dass die gesamte Information aller berechneten Datenpunkte genutzt werden kann und nicht nur der lokale Gradient des letzten bestimmten Datenpunktes. In diesem Projekt stellte ich die theoretischen Grundlagen der Bayesschen Optimierung dar. Die Beschreibung ist als PDF downloadbar.
Simple spelling corrector based on Bayesian inference
In this project I implemented a simple spelling corrector, based on Bayesian inference. I formulated spelling correction as a classification problem and used Bayesian inference to obtain results. Although the basic problem formulation is straightforward, there is plenty room to improve the developed models. I used a simple unigram model as language model and trained it with an EBook of The Adventures of Sherlock Holmes by Sir Arthur Conan Doyle. The implementation is based on chapter 5 of the book „Speech and Language Processing“ by Daniel Jurafsky & James H. Martin. The code was written in a Jupyter notebook, which can be found on GitHub.
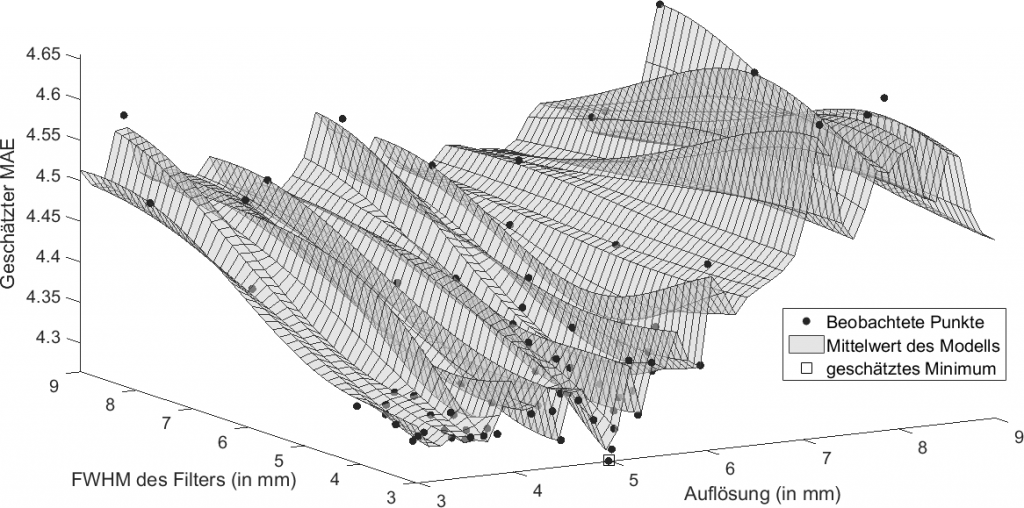
Bachelorarbeit: Optimierung von Vorverarbeitungsparametern bei der Bestimmung des biologischen Alters des Gehirns
Die Altersvorhersage aus MRT-Aufnahmen mithilfe von maschinellen Lernverfahren stellt einen Biomarker für das biologische Alter des Gehirns dar. Die Vorverarbeitung der Aufnahmen beinhalten dabei ein Resampling auf eine bestimmte Voxelgröße und eine Glättungsfilterung. Die Parameter dieser Vorverarbeitungsschritte werden dabei meist willkürlich gewählt. Da auch führende Algorithmen zur Altersbestimmung einen gewissen Fehler enthalten, wurde in dieser Bachelorarbeit der Einfluss der Vorverarbeitungsparameter auf die Genauigkeit der Altersbestimmung und die Möglichkeit der Optimierung dieser Parameter untersucht. Dafür wurden drei Strategien zur Optimierung angewandt und miteinander verglichen. Als Vorhersagemodell für das Alter diente dabei jeweils eine relevance vector regression, die mithilfe einer vierfachen Kreuzvalidierung trainiert und getestet wurde. Die Arbeit ist als PDF downloadbar.
Spam Filter: A binary text classifier with SVMs to separate email-SPAM from email-HAM
The global SPAM volume as percentage of total email traffic is estimated to be somewhere between 60% and 80%. Since for most people email-SPAM is a rather unpleasant experience, various anti-SPAM techniques evolved. Content based filtering system is one of them. Such a filter can be achieved using a binary classifier (in this case SVM) for the two classes „HAM“ and „SPAM“. In this project I implemented a spam filter using a collection of ~60k labeled emails from various sources. As feature encoding the simple method ‚bag-of-words‘ was used. The code was written in a Jupyter notebook, which can be found on GitHub.
Copyright © 2021 Robin Witte